外观
Anthropic 出手,大幅降低 MCP 的 Token 消耗
以前要实现一个 Agent,需要手动完成一个个 API 的接入和调试,现在有了 MCP,接入外部能力的工作简单了许多。
但 MCP 多了之后,模型上下文中塞入了大量的工具定义,导致模型既慢,又浪费 Token。
直到看到了 Anthropic 的《Code execution with MCP: Building more efficient agents》,我才发现 MCP 的调用原来也是可以很高效的。
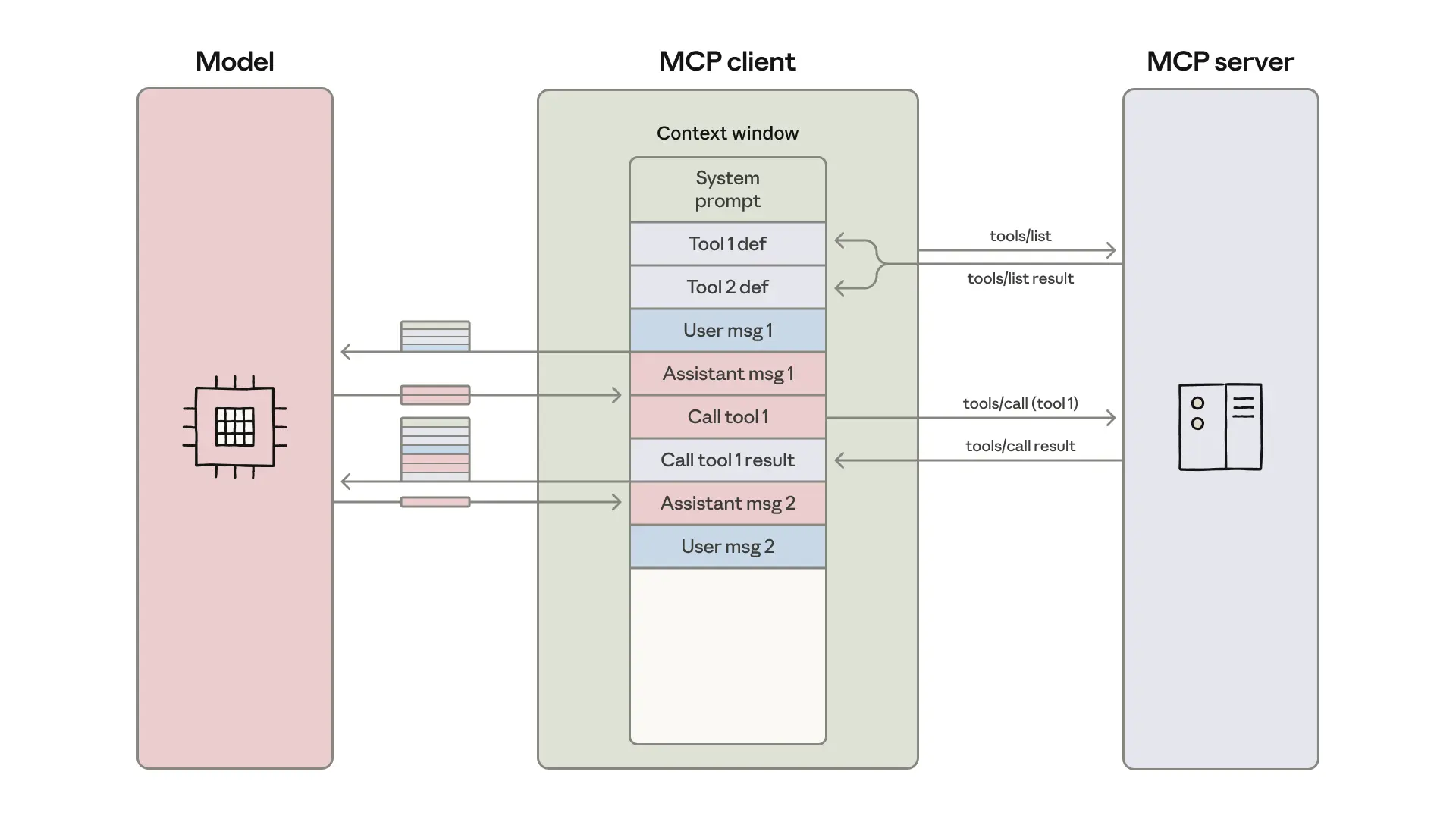
传统 MCP 的效率瓶颈
MCP 在规模化应用中有两个关键短板:
工具定义“占满”上下文
为了让智能体知道如何使用工具,MCP 方式会把所有工具的功能描述、参数要求等加载到模型的上下文中。
在大规模项目中,这些定义信息可能就会占用数十万 Token,不仅拖慢响应速度,还会大幅增加使用成本。
中间结果重复消耗资源
智能体完成复杂任务时,往往需要多次调用工具,并传递中间结果。
比如将云盘文档同步到业务系统,文档会在云盘 MCP 和业务系统 MCP 中多次传输,导致上下文超出限制,甚至任务中断。
解决方案:代码执行
代码执行的核心逻辑,是把 MCP 工具从“直接调用的功能”转变为“可由代码调用的 API”。
智能体不再被动接收全部的工具定义,而是根据需要自动编写代码进行 MCP 调用,这一方案带来了多重提升:
渐进式披露,减轻上下文负担
将工具以代码形式呈现在文件系统上,能让模型按需读取工具定义,而非预先全部读取。

“渐进式披露”的工作流程如下:
1、预加载极简提示: 在 LLM 的上下文窗口中,我们只植入工具的名称、主要参数和功能的精炼代码签名(例如 tool.searchOrders(customer_id: str))。这部分信息占用的 Token 非常少。
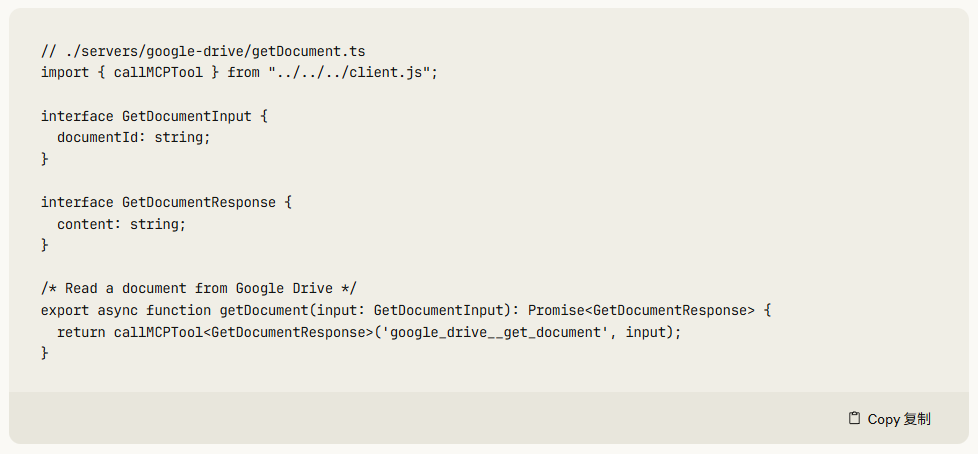
2、Schema 外部化: 所有工具冗长、复杂的 JSON Schema 和验证规则,被移出 LLM 上下文,存储在外部的 MCP Server 的“工具注册中心”。
3、代码触发查找: 当 LLM 生成代码 tool.searchOrders('U456') 并发送给 Server 执行时,Server 才会去其外部的工具注册中心查找 searchOrders 的完整定义,并用它来执行 API 调用。
本地处理数据,减少中间传输
面对大文件、海量数据任务时,智能体可以编写代码,在执行容器中先筛选、处理,最后只需把结果返回给模型,避免大量冗余数据消耗传输 Token。
这个思路竟然与我们上半年实现“问数”的思路类似。不过,我们当时还没有意识到这样节省 Token 传输,我们仅仅是因为 text2sql 不太可靠,采用了智能体调用各种“算子”(各种已有的数据处理类 API)。
简化复杂流程,降低操作成本
在一些复杂场景中,比如系统监控通知、批量处理数据场景中,代码执行模式还可以利用代码的循环、条件判断逻辑,简化实现,减少智能体的反复工具调用,大幅减少延迟及操作成本。
数据隐私保护
除了上述提升效率、降低成本的益处外,代码执行还有一个隐藏的好处。
由于中间结果默认保留在安全的执行环境中,原始数据无需进入模型的上下文,只有统计结果才会返回给智能体,这在很大程度上可以保护用户的数据隐私。
结语
尽管 Anthropic 在某些政策上存在争议,但其在 Agent 道路上的技术探索不得不说非常值得学习。
推荐大家多关注他们的技术博客,收益良多~